
编译原理
目的
通过了解平台从源码到机器可识别的代码的过程,有助于我们理解静态库与动态库的制作,也能有思路去优化app的性能,比如启动速度,还有包括app的”瘦身”计划等。
编译过程简述
首先需要了解一下编译的详细设计,这里有张图可以表示:
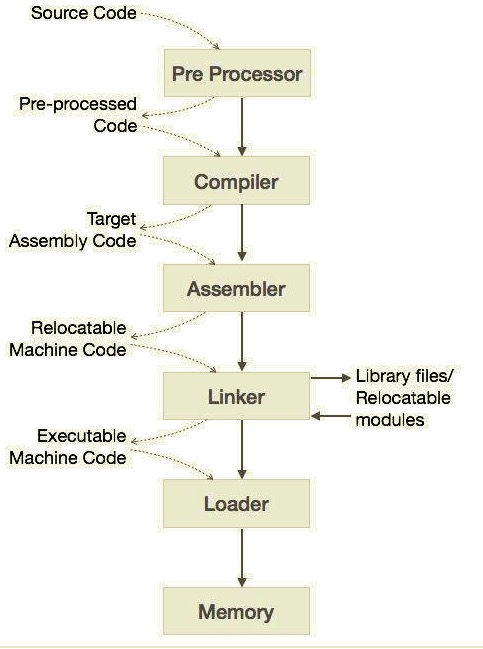
这里简单解释一下就是:
源码开始进行编译,首先第一步就是预处理,主要是进行导入库的源码替换操作,形成修改后的源程序
编译器将处理后的代码编译成汇编程序
汇编器将程序翻译成机器指令,包装成可重定向目标程序,这是一个二进制文件
链接器对依赖的其余目标程序合并到本程序中,生成可执行程序
可执行程序通过加载器加入内存,并由系统执行
为什么会有这样一套流程,原因是计算机无法理解高级语言逻辑,所以我们需要有一套流程能够将高级语言转化成机器可以识别的二进制,这就有了编译器的出现。
编译命令GCC
GCC(GNU Compiler Collection,GNU编译器套件)是由GNU开发的编程语言译器。GNU编译器套件包括C、C++、Objective-C、Fortran、Java、Ada和Go语言前端,也包括了这些语言的库(如libstdc++,libgcj等。)
编写源程序
简单的一个C程序,如下:
1 | |
GCC编译
进入hello.c当前目录下,继续步骤如下:
1 | |
结果:hello,world,由此可以知道刚才是直接将文件翻译成了机器二进制语言文件hello,然后这个文件机器是可以识别的,通过执行,与程序逻辑保持一致,那么我们可以探究一下其中具体做了哪些事情呢,这里有一张编译过程的网络引用图:
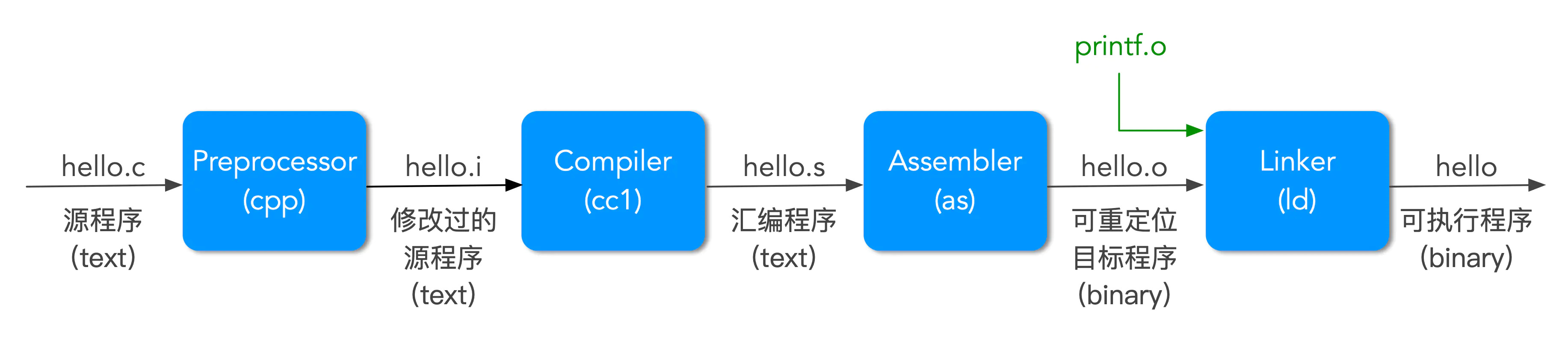
通过这张图,将编译过程进行拆分,可以分为四类:
预处理(text)
编译(text)
汇编(binary)
链接(binary)
预处理
C预处理器,也可以为预编译器,是一个独立于C编译器的小程序,一般简称CPP,即C Pre-Processor,其主要功能用来实现源代码编译之前,实现文本替换
比如这里的hello.c文件,开头里面包含了 #include <stdio.h> ,这里告诉了预处理器需要先系统头文件stdio.h的内容读取后插入到hello.c源程序中来,同时替换掉 #include <stdio.h>
修改后的 C 程序一般另保存为 .i 后缀的文本文件(本例为 hello.i),输出的hello.i 将用于下一个阶段。
编译
编译器CC1,编译器通过将hello.i文件进行编译,得到.s后缀的汇编语言文本文件,这里得到最终结果hello.s。
编译成汇编语言程序有个好处,就是对于不同的编译器,不同的高级语言,都会编译输出一样的汇编程序。
也就是说这一步相当于生成统一的汇编中间代码,就是为了适应不同平台的需要。
汇编
这不操作比较关键,需要理解概念可重定位目标文件 (Relocatable Object File),包含可与其它 relocatable object file相结合的二进制代码和数据,由编译器和汇编器产生。
通过汇编(as)会直接生成可重定位目标文件,也就是实现了汇编语言到机器指令的转化,变成了hello.o的二进制文件,这个时候生成的文件机器已经可以识别,但是别忘了,原来逻辑中还是用了C标准库prinf方法,而目前的生成的hello.o中无法识别prinf的逻辑,所以还会有下一步。
再范围大一些的理解目标文件:
可重定位目标文件
可执行目标文件(Executable Object File),包含可直接复制到内存并执行的二进制代码和数据,由链接器生成。
共享目标文件 (Shared Object File),特殊的可重定位目标文件,可以被装载入内存,并且可以在装载或运行的时候动态地链接。这里比如prinf.o.
链接
在我们生成了hello.o文件后,由于逻辑中依赖了C标准库prinf方法,那么需要一种方法让机器能够识别并且执行,这时候就需要一种方式将prinf.o内容合并进来,那就是链接器的作用。
最后经过链接器的作用后,会生成hello可执行文件,通过loader加载入内存,并由系统执行,也就是./hello,最终整个程序就跑起来了。
- 本文作者:习武
- 本文链接:https://xiwuxisheng.github.io/2022/02/13/iOS/%E7%BC%96%E8%AF%91%E5%8E%9F%E7%90%86/index.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!